Hello! You're probably here through a link in a lab manual. This post is WIP, but I hope I've managed to motivate the need for this algorithm, as well as providing you with a few questions to think about what's really going on under the hood.
You'll find the original research paper for the Raft Consensus Algorithm here - and the website lists a bunch of amazing resources you can refer to as well.
We know that Raft is a Distributed Consensus Algorithm, and while that's right, it's a way of looking at Raft from a "What does it do" perspective, not from a "what problem does it solve" perspective. Keep reading - I'll briefly motivate the problem, and you'll see why this algorithm is necessary.
Motivating the problem
Let's consider that you're the lead backend developer for a hot new startup, fonbuk, which provides people with an online phonebook.
The storage backend for your application is a python dictionary, quite literally this -
{
"user1": {
"ABC": 123567890,
"DEF": 123567890,
"GHI": 123567890,
},
"user2": {
"ABC": 123567890,
"DEF": 123567890,
"GHI": 123567890,
},
...
# And so on
}
The operations on this look as follows - any user can only set and get phone numbers, and these are the interfaces that any sort of clients will use.
def set(phonebook, user_name: str, contact_name: str, number: int):
...
def get(phonebook, user_name: str, contact_name: str):
...
We'll walk through the stages of growth that your company goes through, and the journey you face as the developer.
Stage 0: Single User, Single Machine
- Scale: 10 users per day
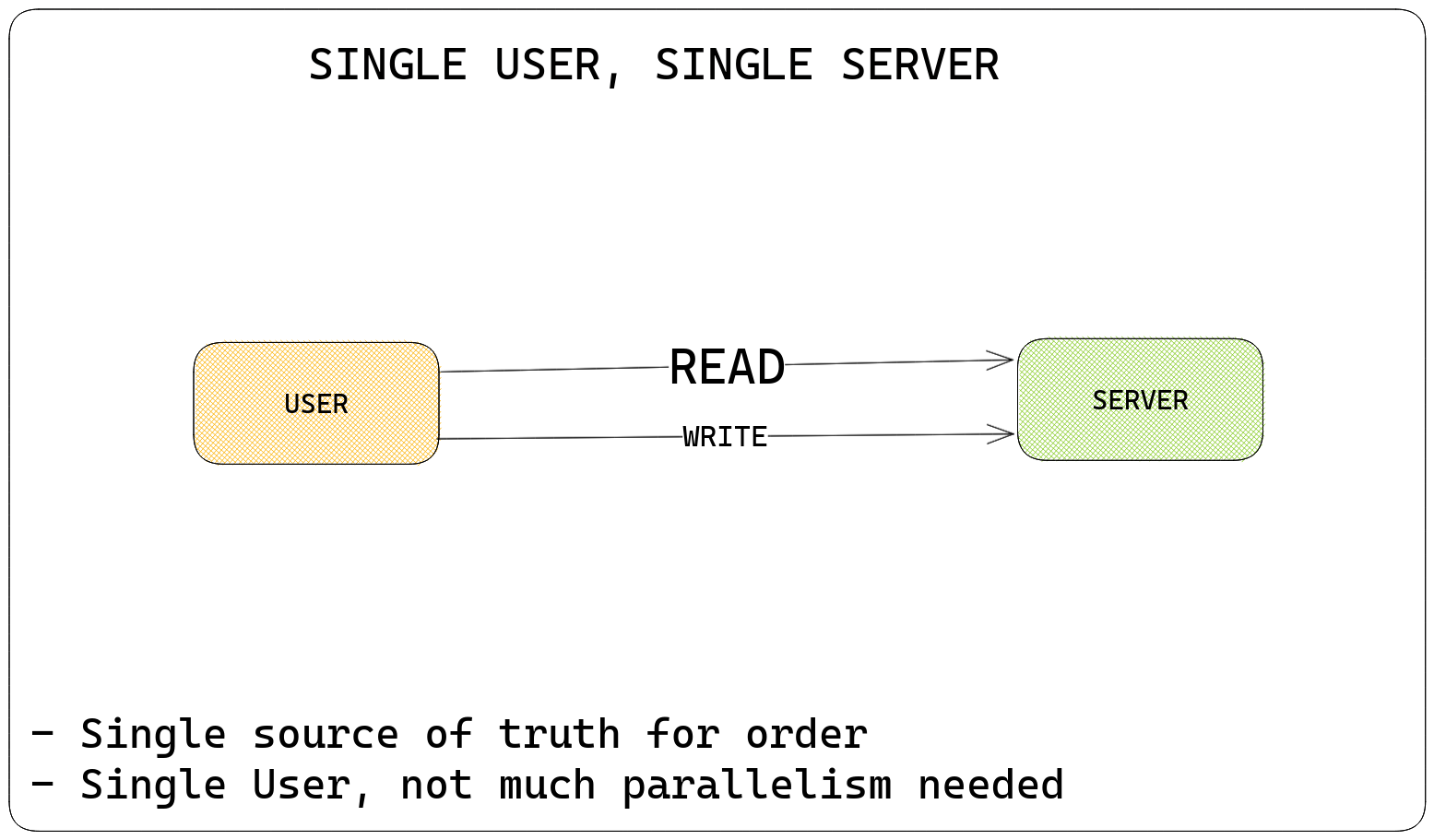
In this part, you're the only user - you get to handle all the queries to read and write numbers, since you're an early-stage startup - so there's nobody else to do this. Your scale, 10 users per day, means you can very comfortably manage to run this on a single machine.
Since you're the only user, you get to decide what order you save phone numbers in - if two people want to change the same contact at once, you decide whose write "wins". This is important.
Stage 1: Multiple User, Single Machine
- Scale: 100 users per day
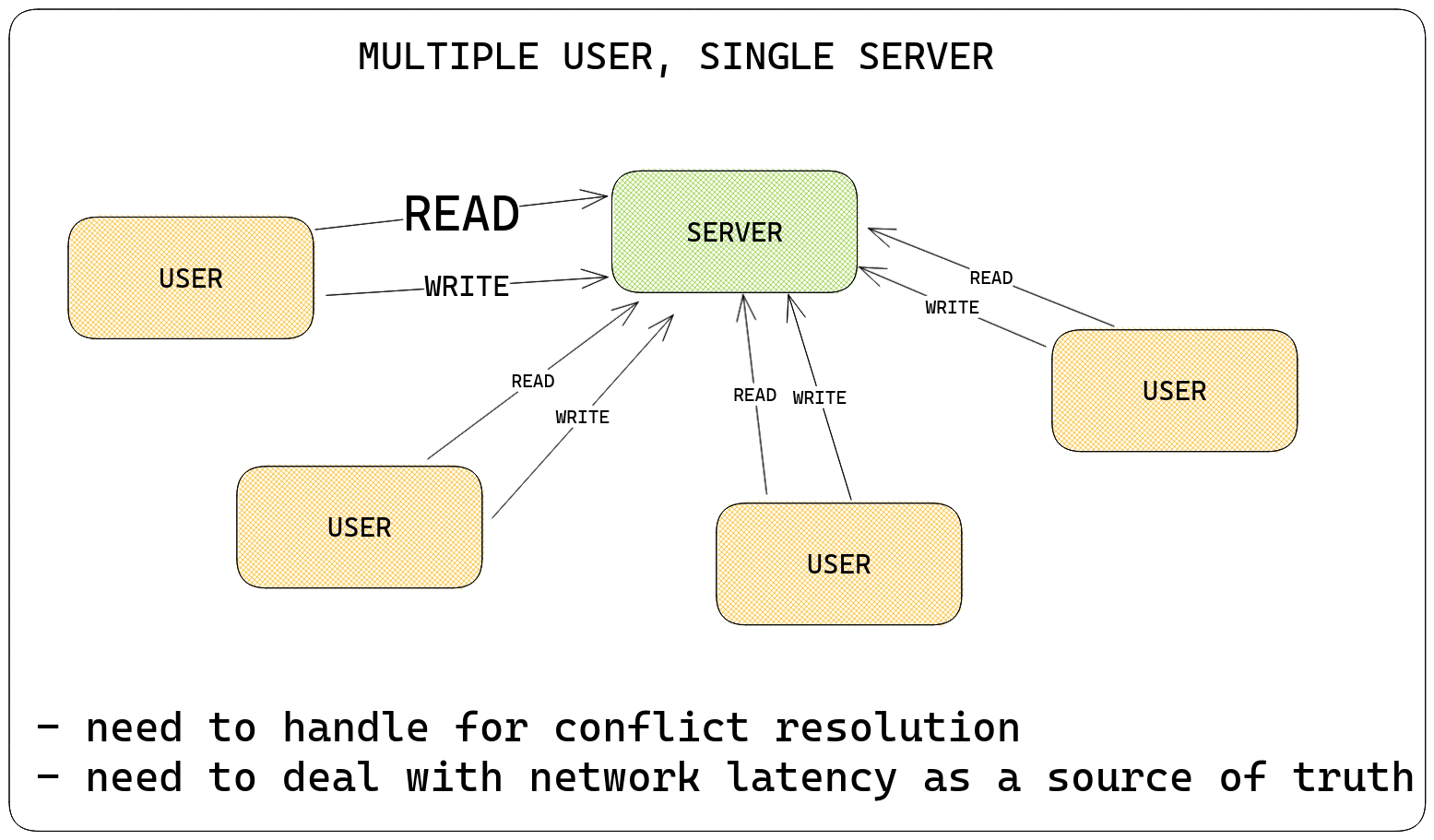
Let's say you manage to make it to TechCrunch Disrupt, displacing title favorites "Pied Piper" for the prize - your innovation has won hearts! People start running toward your app for their phone needs. At this point, you need to handle multiple users!
So, small problem. While your single-user, single-computer model worked fine, you've now got multiple people reading from and writing to the same piece of data. This introduces a bunch of problems, such as -
- If two people write to the same sub-item at the same time, whose write is correct?
- If Person A did
set(pb, "anirudh", "somesh", 123)and then person B didset(pb, "anirudh", "somesh", 123)but Person B's write reached the server before Person A's did, whose write should be considered?
The answer to this is that for "consistency" (i.e. having the "right" value in place according to some scheme), it's necessary for someone to mediate these conflicts. Since you're a capable developer, you implement this - but soon enough, you begin to see some problems.
Stage 1.5: Single User, Multiple Machines
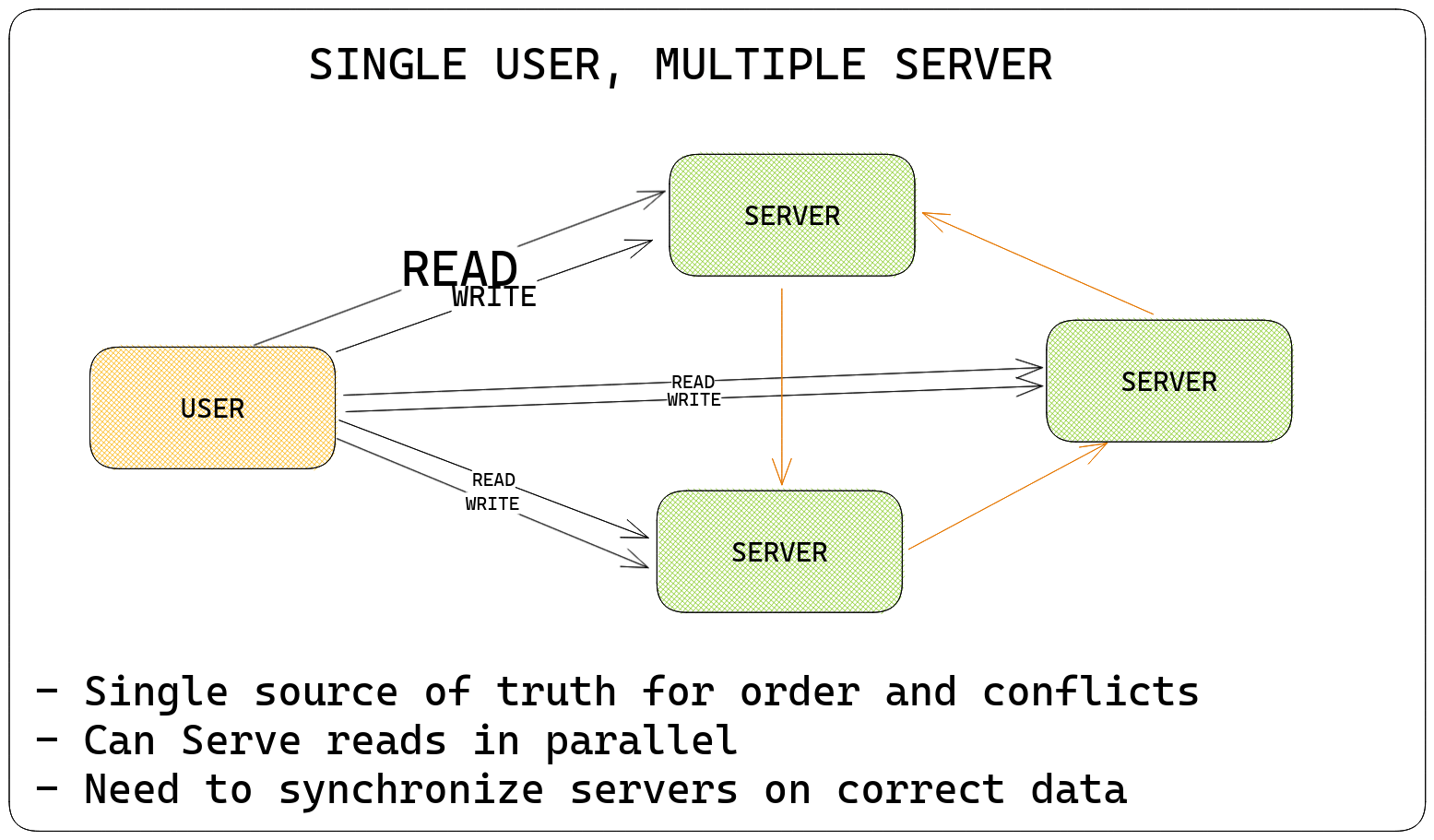
- Scale: 1000 Read-Heavy users per day (reads outnumber writes in a 100:1 ratio)
You decide to carry out an experiment. Computers have limits - there's only so many requests one computer can handle, so you decide - since most people on this application are reading phone numbers rather than writing, I can have multiple computers to handle the read requests.
So, There's only one user who gets to decide the order of things (that's you) and who gets to mediate all conflicts - that's also you.
However, here's a small problem - if you update a value by using set on one computer, how do all the other computers know this value has been updated? Think about it as cache invalidation of a sort. Since there's only one user, you can do what's known as replication to let all the other computers know that something's been changed here, and what it's been changed to.
The challenge here is maintaining consistency between the different copies of state on various machines so that they can handle all these queries independently. Since there's only one person deciding what's being written (you), there are no problems.
Stage 2: Multiple Users, Multiple Machines
Scale: 100,000 Users
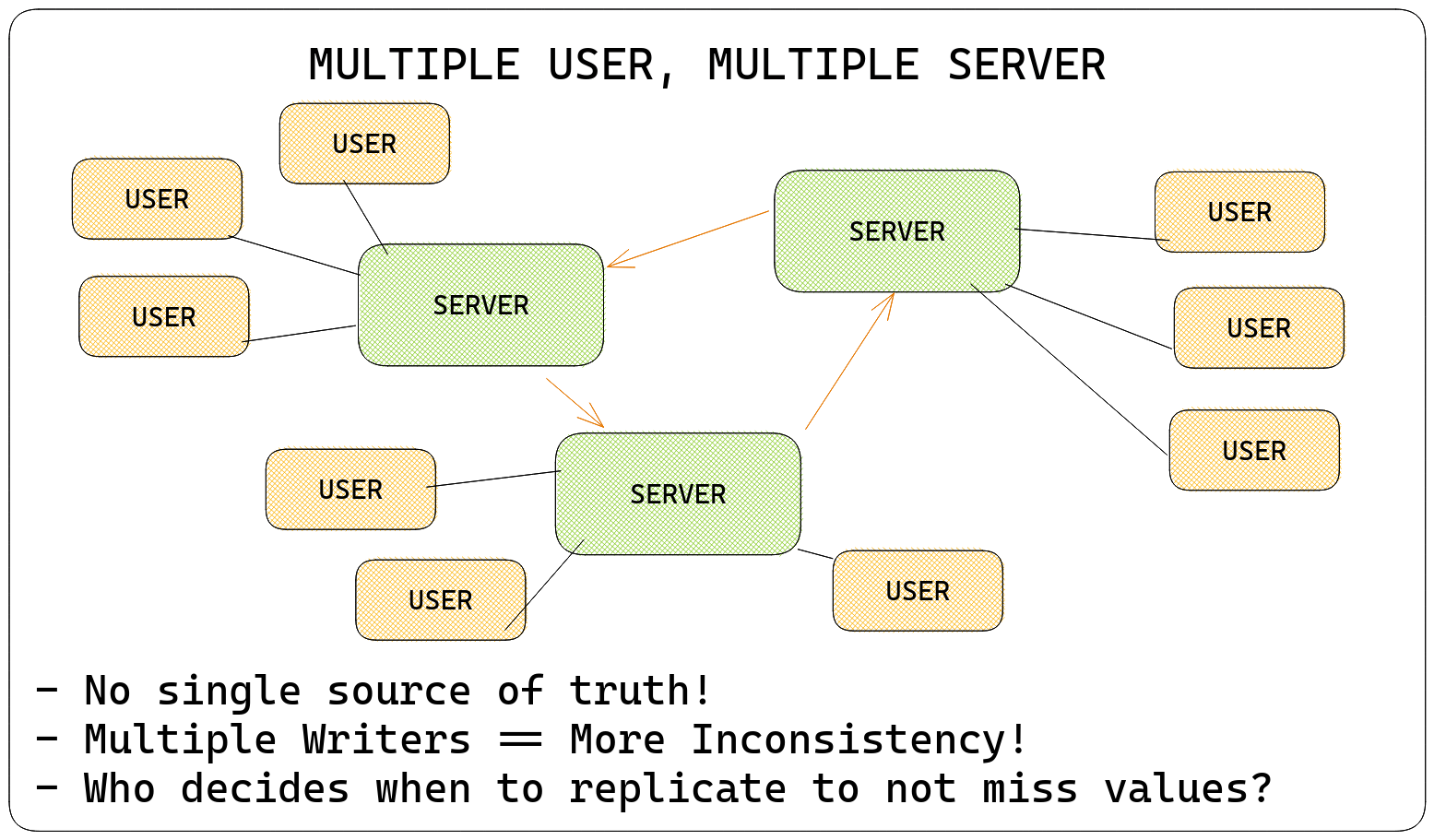
Congratulations on hitting scale! Your startup now needs the best, fastest data solution you have without burning a hole in their pockets - And you come to the rescue! Since you want to take advantage of parallelism, you have multiple machines, and since you don't want to make any user (or human) being the bottleneck, you let people access these machines in parallel.
This brings you to a host of interesting problems, such as -
- There's no centralized conflict resolution - multiple computers may see multiple values as the correct value at any given point in time, leading to inconsistency
- There's no easy way to tell whether or not a computer has the latest value
- If you write a value, there's no guarantee that all computers have recieved that write - maybe some overwrote it!
The Solution
A bunch of really smart people a while back figured out that a good and acceptable (not perfect) solution was to get the computers to agree on whether or not a value should be accepted by everyone as the truth.
This works, because
- All Computers agree on the ordering of writes, so there are no conflicts - taking care of our conflict resolution problem
- All Computers have the same state post-agreement, taking care of our replication problem
- All Computers will only give back the latest value it has, and because all computers agree on any new values, this will be the latest value overall.
Awesome! We now understand what Distributed Consensus is - it's when a bunch of computers agree on a certain decision that should be taken, which all other computers agree to.
What's Raft, then?
Raft is a distributed consensus algorithm that works by separating the problem of distributed consensus into three distinct parts (Leader Election, Log Replication, Safety), and solving each on its own.
The TL;DR Black Box overview is this - Any group of computers using Raft for consensus on any decision will be able to guarantee (within reasonable bounds) that all computers have the same decisions in the same order.
To put it more formally, we can think of Raft as an algorithm to manage a replicated log. If we look at our Phonebook example, it turns out that we can represent operations on that phonebook as a series of log entries.
SET ANIRUDH ABC 123
SET SOMESH DEF 134
The Log above, when applied in the same order, gives you ->
{
"ANIRUDH": {
"ABC": 123,
},
"SOMESH": {
"DEF": 134,
},
}
The Key realization is that the log is a series of actions, and when applied to any FSM, you'll end up in the same state for a deterministic FSM - so if you manage to "replicate" the log of actions keeping the order intect, technically... you've managed to replicate the state! Even then, that has some limitations, but we won't go there today.
Not to mention the fact that you can represent a lot of data structures like this, including databases :)
How does Raft Work?
 Raft Node States: https://www.eecs.berkeley.edu/~rcs/research/raft_fsm.png
Raft Node States: https://www.eecs.berkeley.edu/~rcs/research/raft_fsm.png
Let's assume a cluster of five nodes, each of them in the Follower state by default.
Each of them is equipped with a randomized timer, ticking down from the time the node comes alive. Eventually, someone's timer expires, and when that timer expires, the node (say node 1) stands for election by moving to a candidate state.
All the other nodes in the cluster look at this and go "hey, someone who wants to do my work for me :D let's vote them in", thus, appointing a "term leader" for the current "Term" of the cluster. A term is just a logical clock, and you can think of it as a number that increases every time a new leader is elected.
So, once this leader is voted in a by a majority of the servers, it now has full control - i.e. all writes that all followers need to do get forwarded to the leader, whereas the followers can serve read queries. Remember - All Writes Flow to the Leader! There can only be one leader per term.
Once the leader recieves a write and has made sure that a majority of nodes in the cluster have recieved that write, it can then "commit" that write, which means it's safe for all other machines in the cluster to assume that the value will not be lost in the event the leader crashes.
What happens if the leader crashes?
The leader checks the status of each node in the cluster every once in a while. Every time a node hears from the leader, its timer gets reset.
Simple! Another node whose ranom timer expired will stand for election, become the next term leader, and will then guide the rest of the nodes on what to do. This is why Raft is Fault-Tolerant.
What's the decomposition?
- Log Replication - Leaders have rules on when they can and can't tell nodes to write a value. Nodes, too, will perform a bunch of checks - to see if they request to write is one that's consistent with the previous history of the node.
- Leader Election - Raft's use of timers makes it particularly safe from split-brain problems, such as two leaders in the same cluster - the timers also allow for deterministic randomization of the leader election process.
- Safety - Nodes will only vote a candidate into leadership if the candidate has the latest data. This is determined using term numbers.
This decomposition not only makes the algorithm easier to understand but also easier to build.
Overarching WIP Conclusion
You definitely should learn Raft. This visualization is an excellent one - try doing all sorts of things like stopping nodes, adding new ones, and so on.
We start clean.
Hello! Let's understand the Raft Consensus Protocol.
You might be asking - What the hell is Raft? And you're right. there's no clear answer. Is it a boat? is it a plane? Is it Batman? And these are all valid questions. There's only one right answer, which is that Raft is a distributed Consensus Algorithm.
Sometimes just one computer isn't enough, ya know? Sometimes you just need more juice. Sometimes your one dusty old AMD Athlon Dual Core from 2006 can't keep up with the load, which means you need to scale.
Scaling, our benevolent dictator, manifests for computers in two ways - Vertical Scaling and Horizontal Scaling.
- Vertical Scaling Increasing the amount of CPU, RAM, Disk Space available on each machine - as you go higher, this becomes prohibitively expensive
- Horizontal Scaling Get a bunch of lower-power machines and make them process the data in parallel! It's automatically parallel without switching overhead et al and is also cheaper.
Since vertical scaling has its limits and is expensive, horizontal scaling is often the recommended option. You'll see some notable holdouts to this - such as Stackoverflow - but I digress.
Ultimately, if you want multiple machines coordinating on some single task, you'll need them to talk to each other to figure out what to do and how to do it! In some cases you usually have someone coordinating these things (a la Zookeeper, HDFS, etc) or you have these decisions being made autonomously amongst these machines themselves, without you having to appoint a "leader".
Getting machines separated by a network, all working towards the same thing (i.e. a Distributed System) to agree on a descision (one thing) is known as a consensus algorithm.